This section presents an overview of the software instrument system that has been developed as a tool in this project, constituting the main method for the performative exploration of musical features of speech through improvisation. Through the affordances of this instrument, much about the music can also be explained, and implicit in this technical description is therefore also an account of the musical choices, methods and possibilities arrived at in this project. The instrument system is a solution to the particular musical challenges posed by this project, and provides the practical foundation and means for the musical exploration. Its final design is the result of a long chain of aesthetical choices, as well as changes made in direct response to shortcomings identified through musical explorations.
Digital musical instrument context
The system can be classified as what is generally known as a Digital Musical Instrument (DMI). In the context of such digital musical instruments, several existing instruments have been developed based on voice and speech, many of which have been concerned with direct voice synthesis in a traditional gesture-to-sound instrument paradigm. Recent contributions include systems that control various kinds of voice and speech synthesis techniques by means of hand gestures, either on a modified accordion (Cook & Lieder, 2000), with gloves (Fels & Hinton, 1998), stylus (Delalez & Alessandro, 2017), guitar (Astrinaki, D’Alessandro, Reboursière, Moinet, & Dutoit, 2013), microtonal keyboards (Feugère, D’Alessandro, Doval, & Perrotin, 2017), or using motion capture to track hand gestures in space (Beller, 2014; Beller & Aperghis, 2011). Other systems have taken the opposite approach, using voice as input to control other kinds of synthesizers (Fasciani, 2014; Janer, 2008). The present system also use speech as input, and has also the ability to produce synthesized speech output, but unlike the traditional instrument paradigm where expressive performer gestures are used directly to control sound production, this system could rather be seen as a kind of real-time compositional tool that can be used to analyze and extract, transform and arrange several layers of rhythmic, melodic, harmonic and other musical features from a given speech source. As a concept, this is not unlike transcribing and scoring speech melodies on paper or electronically processing speech and composing an electroacoustic piece, but to do this through the dialogical process of improvisation it needed to be a real-time interactive instrument-like system.
Functional requirements
Few specific functional requirements for this instrument were clear from the start. Following the decision to focus on real-life conversations and speech genres rather than spoken performances on stage, the system had to be based on recordings of speech and not primarily live speech input. In addition, and as described above, to be used for improvisation it needed to work in real time and be playable like an instrument. It was going to be based on analyses of speech and have some means for generating sound based on these analyses, but other than that I could not really foresee exactly what features would turn out to be interesting and useful beforehand. In that sense, the development of this digital musical instrument was different from building a system where the functional requirements are known in advance. The instrument development process became an integral part of the musical exploration of different ideas and approaches to speech as source material for music making. This changing and evolving nature is common for many such complex digital performance instruments where new ideas are developed and tested continuously (Trifonova, Brandtsegg, & Jaccheri, 2008).
Platform/Software Environment
Regarding the actual programming, the software instrument has been developed for use on conventional personal computers in the popular Max graphical programming environment, relying on some very useful external Max libraries of analysis and processing tools developed at the Institut de Recherche et de Coordination Acoustique/Musique (IRCAM): at first the FTM (“Faster Than Music”) library (Schnell, Borghesi, & Schwarz, 2005) and later also the MuBu (“multi-buffer”) external library (Schnell, Röbel, Schwarz, Peeters, & Borghesi, 2009).
For more information on the various signal processing techniques used, see the technical background in the appendix, and for detailed descriptions of the actual implementation of these techniques in Max, please refer to the comments in the actual Max patches available from the downloads page.
A fairly detailed technical description of the software instrument system and its different parts is presented below. Again, the purpose of this is not only to show how it works from a technical perspective, but as much to show the affordances and musical choices that has been developed through several rounds of design, practice and performance, and which in the end constitutes the practical foundation for the artistic outcomes of this project.
System overview
A digital composed instrument such as this can be viewed as composed of many processes that can be classified in terms of their function, such as analysis, transformation, and synthesis (Schnell & Battier, 2002). This is a useful division that has served as a guideline for my modular approach to building a playable digital instrument. In this instrument, speech recordings fulfil the function of performer gestures usually used input for an instrument. The performer in turn controls both the selection and playback of the recorded speech segments, as well as how these recordings are translated into musical structures. A helpful concept in this regard is the metaphor of “orchestration”, describing the process of arranging and distributing the musical structures extracted from the speech material.
Below is a short video featuring a basic overview of the system.
Video example: System demonstration #1, overview:
In the diagram below, a schematic overview of the whole system shows the different parts and their function within the system.
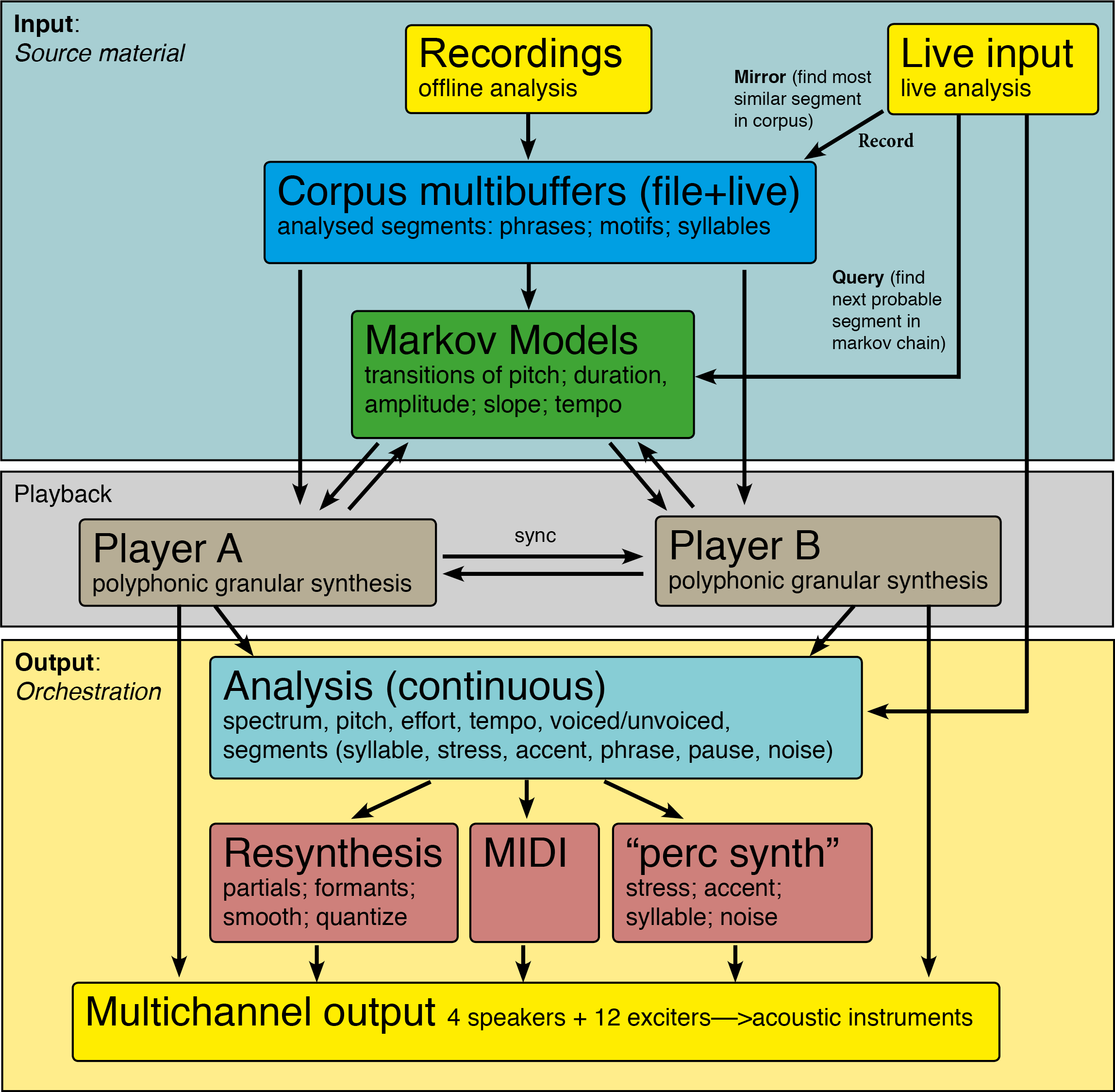
Input: speech recordings
At the core of the system is a set of buffers for loading or recording collections (corpora) of speech recordings. The recordings can be analysed and automatically segmented into syllables (or more precisely: vowels), stressed syllable motifs and breath length phrases. For all these segments, five basic prosodic/musical descriptors are calculated: mean pitch, segment duration, amplitude, pitch slope and tempo. Collections of analysed recordings can be saved as corpora that can be recalled on the fly during performance, eliminating the need to perform such segmentation every time a collection of recordings is needed.
Machine Learning
Organizing recordings as collections or corpora also allows the possibility of using statistical analyses in order to “learn” the characteristic patterns in a corpus, known as machine learning. The system includes a simple technique for such machine learning known as Markov chains. In short, this technique analyses the likelihood of any transitions between different stages in a chain of events, and based on that model one can generate new chains that are statistically as probable, and therefore display some of the same overall structural characteristics without using the exact same order of individual segments. In this system, when a corpus is loaded, its segment’s descriptors are used to generate such Markov models that describe the likelihood of transitions between any states in the corpus: between different pitches, durations, amplitudes, pitch slopes and tempi. How these statistical models then can be used to generate alternative sequences is described further below.
Playback
The recordings segments can be played back by two identical player devices, which can either be operated separately, or synchronized to create unison or shadowing effects. Playback is technically handled as pitch synchronous granular synthesis (Roads 1996, p.174), which means that it reproduces “sound grains” of one wave period at a time, at the frequency defined as the fundamental pitch. As reference for this fundamental frequency it uses a pitch track generated and stored in the buffer as part of the initial offline analysis and segmentation processing. The pitch-synchronous granular synthesis technique allows decoupling of playback speed and pitch, as the grain rate can be changed regardless of the original fundamental frequency indicated by this pitch track. This enables playback speed transformations like time stretching and compressing, independently from frequency transformations like pitch and spectrum transpositions. It also allows independent changes to the timing of segment onsets, making changes to the overall speech rate or tempo of syllables possible.
Video: System demonstration #2, playback device:
Playback control
As a result of the database organisation which helps keeping track of all the segment and their boundaries and descriptors, segments can be sorted and navigated in a graphical user interface based on their sonic features, displayed in a scatter plot as a function of mean pitch (y) tempo/duration (x) and amplitude (colour). Number of voices available for polyphonic playback can be set from one to eight, and a quantity measure allows up to 10 of the most similar segments to be triggered at the same time as a cluster or as a sequence (depending on the number of available voices), optionally repeating in a random order. If, however, the Markov chain mode is enabled, each triggered segment will query the Markov model for probable transitions for each of the segment’s descriptors. These probable transitions are in turn used to find and trigger the closest matching segment in the corpus (this approximation enables output even when no exact matching segment is found, thus avoiding the dead ends typically a problem when generating new Markov chains from a limited dataset). In effect, this generates Markov chains of alternative but statistically probable sequences of segments. The degree of freedom for these sequences can further be limited with an imposed measure of continuity, influencing which descriptors are prioritized when searching for the closest matching segment. Ranging from 0% continuity where all musical descriptors are weighted equally, through 50% where only pitch and duration are weighted, towards a state at 75% where the file index is weighted as most important thus limiting segment choice to only those of the same recording file. When the continuity measure is set fully to 100%, only the file and segment indices are weighted when searching for the next segment, forcing a perfectly continuous playback of segments in their original order. This way, just by changing the continuity measure, one can move gradually from a linear sequence of segments to a probabilistic sequence and vice versa, as demonstrated from 1:17 in the video demonstration above.
Continuous analysis and synthesis devices
The sound output from the playback devices can be fed into an online analysis stage, performing real-time segmentation and analyses of spectrum, fundamental pitch, vocal effort and tempo. Due to the modular layout, the resulting stream of continuous analysis data can then be used collectively by a number of synthesis devices, making it possible to create many different and simultaneous layers of orchestration based on the same speech input. In the present setup that includes an additive synthesizer, a MIDI-note output device and a hybrid audio/midi percussive device.
The modular layout also allows these devices to have separate but similar controls for the transformation, synthesis and output of the same incoming continuous analysis stream, as shown in the diagram and video demonstrations below.
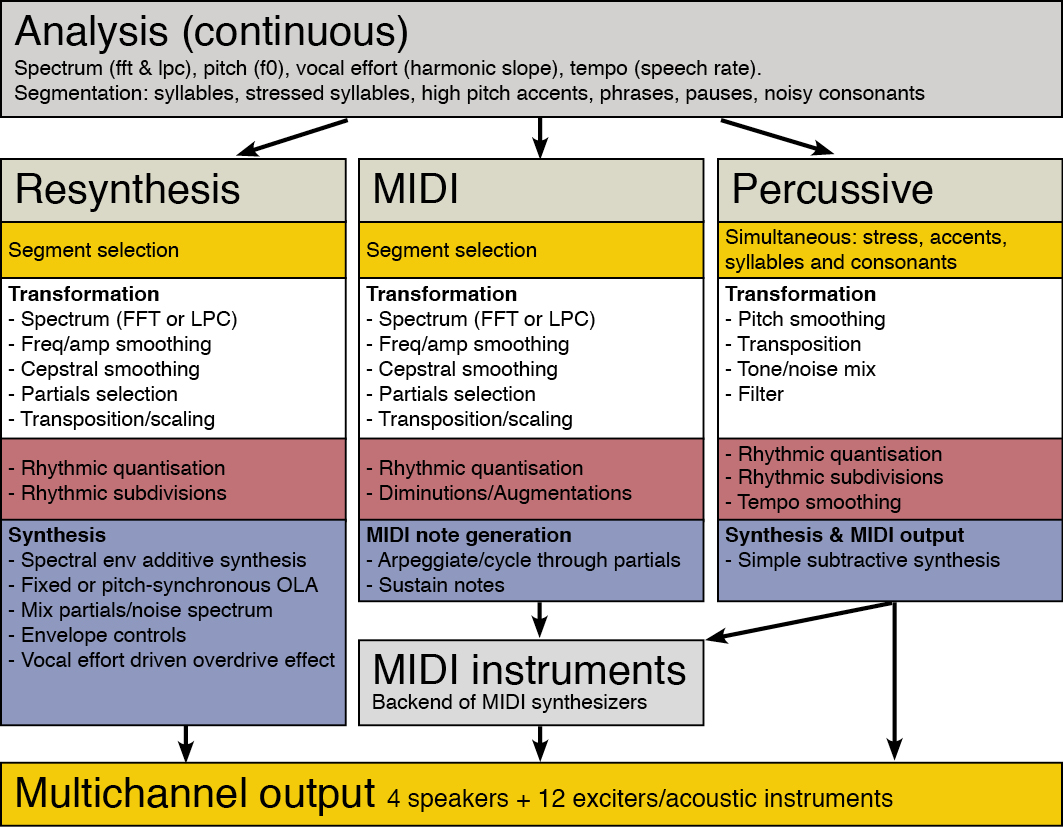
Devices overview
Video example: System demonstration #3, synthesis device:
Video example: System demonstration #4, MIDI device:
Video example: System demonstration #5, percussive device:
Sound output
The sound of all playback and synthesis devices can either be mixed to a stereo output or routed to multiple output channels. In the current setup, 16 channels are used, connected to a set of stereo loudspeakers, two small low fidelity radios, and 12 transducers attached to acoustic instruments resulting in a hybrid “electric/acoustic” sound. This unorthodox multichannel setup is reflected in a panning interface where the sound position can be controlled, not as an exact “panorama” position in the room, but sent to the different speakers and instruments in a kind of direct orchestration of the sound output. In line with the general metaphor of orchestration, this “orchestra” of loudspeakers and acoustic instrument-speakers is organised into sections of four different instrument classes: speakers, drums, strings and cymbals, with four instruments/speakers in each group. The physical interface consists of one joystick for panning between the instrument sections, and another for panning within the groups. Thus, with these two controllers, one can move the sound gradually between any of the 16 outputs of the system (shown at 2:54 in the video demonstration of the playback device above).
In addition to these controllers, an “autopan” function can change the pan position automatically at segment onsets, either as a range within the same instrument group or across all outputs.
MIDI channel routing is handled in a similar way, sending MIDI notes to a backend of 16 software instruments (for convenience hosted in the popular music production software Ableton Live), but the sound output from these software instruments is routed to the same multichannel outputs of transducers and speakers, resulting in a coherent and intuitive layout for controlling multichannel pan position for all audio and MIDI devices in the system.
Live sound input
In addition to the signal flow described above, it is also possible to feed live audio input into the system. This input can be used in three very different ways. Sound can be recorded in one of the buffers and instantly be available for playback. It can be analysed and used to trigger playback of segments that are already in the buffers, either by finding the most similar segment (mirror mode), or by triggering a response by querying the Markov model for a statistically probable continuation of the input segment (query mode). Finally, audio input can also be routed directly into the online analysis stage for instant live orchestration by any of the synthesis devices.
Control and automation
The whole system can be controlled with a conventional graphical user interface (GUI) with dials, sliders and switches. Physical MIDI controllers can be connected and mapped to these control parameters by an automatic learning function. The same centralized parameter subsystem is used for storing and recalling presets both globally and for each “device” in the system. Through accessing this subsystem, it has also been possible to enable complete automation of any parameter in the system by scripting cue files, a feature that was implemented in order to use the system in a complete self-playing mode for use as a sound installation.
Technical affordances
How the particular features of this instrument system have been used in music-making is described further in a chapter below about performance methods. As stated above, the possibilities of the system are based on a combination of linguistic phenomena, musical ideas and instrumental needs identified through testing and performance. But in addition to this, the technical development of an instrument has in itself contributed to the musical ideas, generated from the encounter with certain technical possibilities provided by the system. The technical development process often involved the creative use (and abuse) of different techniques just to explore how they would sound and if something interesting would happen. One example of this can be provided by the result of heavy cepstral smoothing. Reducing the frequency spectrum to just a few wide frequency bands, it can result in an apparently formalistic play between high and low registers, quite abstract but nevertheless conveying some dynamic traces of the original speech gestures.
Cepstral smoothing example:
Another example of such technically derived ideas is the possibility to express vowel formants as musical chords. Formants are the characteristic spectral peaks that define vowels, and are not usually expressed or perceived as individual pitches, but act more like filter frequencies that shape the spectrum of a source sound. But if synthesizing the formant frequencies directly, it is fascinating how just a few formant frequencies are enough to render speech intelligible, even with no fundamental pitch present. Using the Linear Predictive technique to track formants and output the resulting frequencies as chords can result in an interesting abstraction of this “almost intelligible” spectral shape of speech.
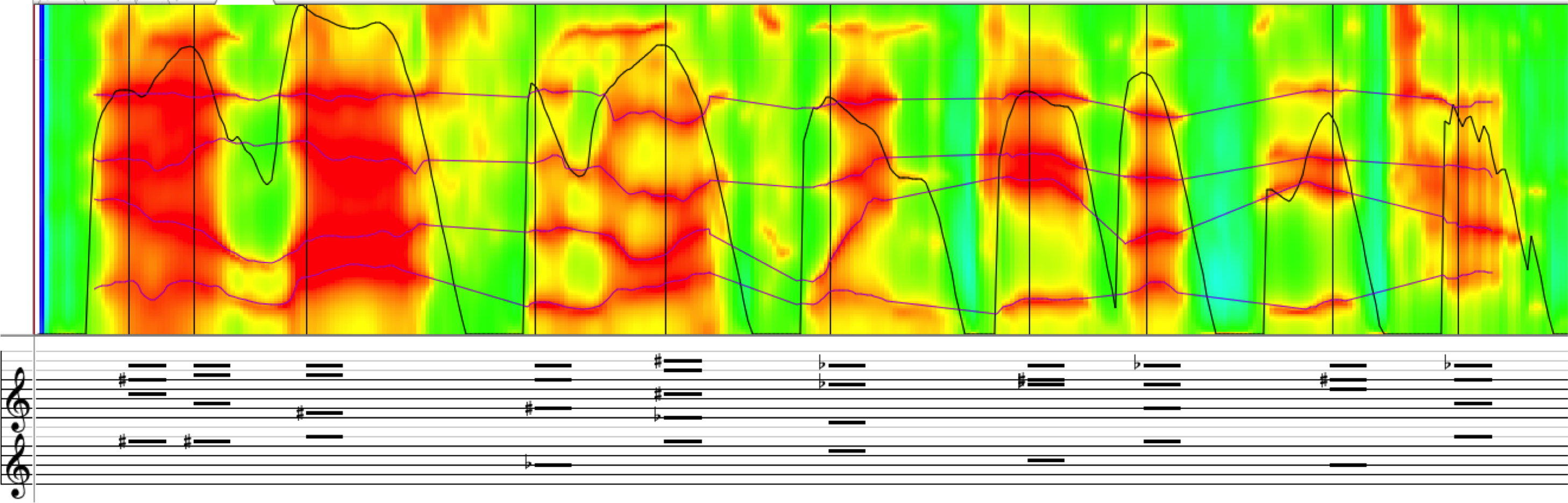
A mel-frequency spectrum showing the four lowest formants and the corresponding musical chords transcribed from the sound example below.
Sound example of iterative transformations of formants into abstracted chord sequences:
In addition to these technologically inspired ideas, purely musical ideas have of course also driven development of the instrument system and the music it can produce. The motivation was always to make music and not didactic demonstrations, so at some point it is absolutely necessary that intuitive associations and connotations take over in the further process of making music from the speech sources. This can for example be the creation of complex polyrhythmic layers, not really a part of speech at all, but inspired by speech tempo variations or based on some strong rhythmical feature typical of a speech genre and therefore still related to this material. Or it can be stretching out vowels and layering several voices to create dense microtonal choral textures, only using the vowel timbres from speech to pursue an otherwise abstract musical idea:
In this way, both prosodic features, speech genres, technical possibilities and original musical ideas have contributed in shaped the affordances of the instrument system and served as starting points for music making, presenting interesting phenomena that generate new sonic ideas, explored further through musical discourses with the speech material.
A more thorough review of the system’s possibilities and limitations is provided below in the chapter entitled “Reflections on the design, development and performance of a new instrument”. But before that, we must turn to how this software instrument evolved into a coherent performance setup through developing a concept of sound and orchestration.
| ← Previous page: Methods of abstraction | Next page: Sound and orchestration → |
References
Astrinaki, M., D’Alessandro, N., Reboursière, L., Moinet, A., & Dutoit, T. (2013). MAGE 2.0: New Features and its Application in the Development of a Talking Guitar. In Proceedings of the International Conference on New Interfaces for Musical Expression. Daejeon, Republic of Korea: Graduate School of Culture Technology, KAIST. Retrieved from https://nime.org/proceedings/2013/nime2013_214.pdf
Beller, G. (2014). The Synekine Project. In ACM International Conference Proceeding Series.
Beller, G., & Aperghis, G. (2011). Gestural Control of Real-Time Concatenative Synthesis in Luna Park. In P3S, International Workshop on Performative Speech and Singing Synthesis. Vancouver, Canada.
Cook, P. R., & Lieder, C. N. (2000). SqueezeVox: A new controller for vocal synthesis models. In ICMC.
Delalez, S., & Alessandro, C. (2017). Vokinesis : syllabic control points for performative singing synthesis. In Proceedings of the International Conference on New Interfaces for Musical Expression (pp. 198–203).
Fasciani, S. (2014). Voice-Controlled Interface for Digital Musical InstrumentS. PhD Thesis, National University of Singapore.
Fels, S. S., & Hinton, G. E. (1998). Glove-Talk II – a neural-network interface which maps gestures to parallel formant speech synthesizer controls. IEEE Transactions on Neural Networks, 9(1), 205–212. https://doi.org/10.1109/72.655042
Feugère, L., D’Alessandro, C., Doval, B., & Perrotin, O. (2017). Cantor Digitalis: chironomic parametric synthesis of singing. EURASIP Journal on Audio, Speech, and Music Processing, 2017(2). https://doi.org/10.1186/s13636-016-0098-5
Janer, J. (2008). Singing-driven interfaces for sound synthesizers. Universitat Pompeu Fabra.
Roads, C. (1996). The computer music tutorial. Cambridge, Mass.: MIT Press.
Schnell, N., & Battier, M. (2002). Introducing Composed Instruments, Technical and Musicological Implications. In Proceedings of the international conference on new interfaces for musical expression (pp. 156–160). Dublin, Ireland.
Schnell, N., Borghesi, R., & Schwarz, D. (2005). FTM : Complex Data Structures For Max/Msp. In Proceedings of International Computer Music Conference (ICMC).
Schnell, N., Röbel, A., Schwarz, D., Peeters, G., & Borghesi, R. (2009). MUBU & friends – Assembling tools for content based real-time interactive audio processing in MAX/MSP. In Proceedings of International Computer Music Conference (pp. 423–426).
Trifonova, A., Brandtsegg, Ø., & Jaccheri, L. (2008). Software engineering for and with artists: a case study. In Proceedings of the 3rd ACM International Conference on Digital Interactive Media in Entertainment and Arts (DIMEA’08) (Vol. 349, pp. 190–197). Athens, Greece.
| ← Previous page: Methods of abstraction | Next page: Sound and orchestration → |
